
■ 내용
1. 기능 설명
2. 분산 – 통계에 대한 기본적인 이해
3. Var 함수 구문/사용법
4. Var 함수를 사용해보십시오 – 분산 찾기
** 키 요약
– 오늘은 통계함수인 Var함수에 대해 알아보겠습니다.
– 사실 통계는 어렵고 엑셀 var함수는 어려운 부분이 없습니다. ^^
– 제가 전공이 아니라서 제가 아는 부분만 설명드릴테니 그냥 읽어주세요.
– 이런 것의 개념적인 부분과 주의해야 할 부분을 이해하셔야 할 것 같습니다.
1. 기능 설명
– 엑셀 형식으로 통계함수 중 var함수는 분산을 계산하는 함수이다.있습니다.
– 흩어지는 경우 데이터 세트가 중앙값인 평균으로부터 얼마나 떨어져 있는지(=멀리) 나타내는 통계 수치입니다.
– 합계 ( ( x – avg ) ^ 2) / n으로 공식화그리고
– 모든 데이터를 가지고 평균값과의 차이를 찾아 제곱하면 음수/양수의 합이 0이 되지 않고,
– 평균과의 차이는 제곱이므로 차이가 클수록 영향이 큽니다.
– 실제 일탈 정도를 평가하기 위해, 표준 편차(Stdev 함수) 또는 CV(변동 계수 = Stdev / avg)는 종종 변동 계수로 사용됩니다.그래요
– stdev 함수나 cv의 기본 개념을 이해할 수 있다.
– 그리고 참고로 실무에서 일탈이 중요한 이유는 일탈에서 진정한 실력과 전략이 나오기 때문입니다.
– 평균 점수가 70점이라 하더라도 모든 과목에서 70점을 받은 학생과 평균 70점으로 50점, 100점, 60점을 받은 학생의 공부 전략은 다릅니다.
– 프로세스의 능력이 같은 의미로 해석되기 때문에 다른 전략이 필요합니다.
– 그리고 항상 무언가의 성능을 분석합니다. 가장 기본적인 통계분석은 평균(average function), 표준편차(Stdev function), CV(Stdev/Average function)이다.
– 그리고 출발지가 분산되어 있어서 그렇게 사용하는 기능은 아니지만, 어떤 기능인지, 어떤 내용인지 알아두시면 좋을 것 같습니다.
– 통계분석에서 늘 헷갈려하는 모집단과 표본집단에 대해 간략히 이해하는 기회가 되었으면 합니다.
– 두 함수가 다르고 결과값도 다르지만 항상 헷갈리는 부분이 있음 그렇다면 어떤 기능을 사용해야 할까요?보지마.
– 모집단과 표본집단의 정의와 모집단이 this일 때 사용하는 함수와 표본집단이 this일 때 사용하는 함수에 대해 자세히 설명한다.
– 이제 어떤 기능을 사용해야 할까요? 명확하게 말하는 것을 찾기가 어려운 것 같습니다.
– 결론부터 예측을 해보자. 이들 중 대부분은 샘플 그룹(Var 또는 Var.S 함수)입니다. 모집단은 이상적인 전체 집단을 가리키며 종종 변하지 않는 값이기 때문입니다.
2. 분산 – 통계에 대한 기본적인 이해
– 사실 저는 통계학과 학생이 아닙니다.
-실무적으로 데이터를 분석하는 일이 많기 때문에 통계에 관심이 있는데, 내가 이해하는 수준이다.
-통계 개념이 다르다는 걸 이해하시면 될 것 같아요.
– 1) 분산: 평균에서 벗어난 정도
– 그래서 데이터 집합을 평균하고 모든 데이터에서 평균을 빼면 (데이터 – 평균) 중심에서 얼마나 멀리알 수 있습니다.
– 서로 다른 숫자를 모두 더하면 +/-가 되고 합계는 0이 됩니다. 데이터 세트의 “평균에서 벗어난 정도”를 찾을 수 없습니다.
– 그렇게 나온 컨셉 차이는 제곱됩니다( = (데이터 – 평균) ^2 ). 이 경우 모든 차이점은 양수입니다.
– 제곱값을 모두 더하면 “평균으로부터의 편차 정도”가 나옵니다.
– 그리고 마지막으로 데이터 개수로 나누면 분산을 구할 수 있습니다.
– 이때 모집단의 경우 데이터 수 n으로 나누고 표본 그룹의 경우 (n-1)로 나눕니다.


– 2) 분산: 모집단의 분산, 표본집단의 분산
– 약간 헷갈리는 개념이 나옵니다. 그들은 모집단과 표본입니다. ㅠㅠ
– “인구”는 영어로 인구를 의미하며 전체 인구를 의미합니다.보지마.
– 한국 사람의 평균 키를 알고 싶다면 인구는 “대한민국 전체 인구”를 의미하고,
– 모집단의 평균, 분산 및 표준 편차 값은 고정 값, 즉 상수입니다. 우리가 모르는 것뿐입니다.
– 주어진 제품을 10,000개만 생산한다면, 10,000개를 모두 측정하여 평균, 분산, 표준편차를 구하면 모집단의 통계자료입니다.
– 그러나 대부분의 경우 현실적으로 모두 측정하기는 어려우며 이 경우 좋은 샘플을 선택하여 계산한다.
– 이와 같이 표본 데이터의 통계적 값을 표본 집단의 평균, 분산, 표준 편차라고 합니다.
– 영원불변의 참 전체의 가치를 알고 싶다. 나는 부모 그룹에 대해 이야기하고 있습니다.
– 다 알고 싶은데 현실적으로 불가능하다.. 그럼 패턴군 얘기다.
– 그리고 대부분의 데이터는 표본집단이다. ^^
– 그렇게 모집단을 데이터 수인 n으로 나누어 분산, 표준 편차 등을 구합니다.
– 표본집단은 데이터의 수를 하나씩 줄이고 n-1로 나누어 분산, 표준편차 등을 구한다.
– 그리고 표본집단의 수가 무한히 많아지면 모집단 = 표본집단이 된다.
– 대부분 잘 모르시면 그냥 표본집단으로 계산하시면 됩니다.
– 엑셀에서는 모집단과 표본집단의 분산을 계산하는 함수가 아래와 같이 다릅니다.
– Population Variance: VAR.P 함수 (VARP 함수 – Excel 2007 이전 버전 함수)
– 표본군 분산: VAR.S 함수(VAR 함수 – Excel 2007 이전 버전 함수)
– Excel이 함수 이름을 변경했습니다. VAR 함수는 VAR.S 함수가 되고 VARP 함수는 VAR.P 함수가 됩니다.
– 둘 다 사용 가능하나 VAR.S, VAR.P 기능 사용을 권장합니다.
– Var, Varp, Var.S 및 Var.P 함수는 모두 구문 및 사용법이 동일합니다.구버전, 신버전, 모집단/표본군을 구분하여 사용하는 정도이다.
3. Var 함수 구문/사용법
– 다음 구문은 엑셀 도움말에 대한 설명입니다. Excel 함수의 전체 구문을 기억할 수도 없고 기억할 필요도 없습니다.
– 단, 엑셀 도움말 및 기능을 사용할 때 표시되는 풍선도움말의 조건에 익숙해져야 하므로 기회가 되면 보시기 바랍니다.
– VAR(숫자1, (숫자2),…)
– 1번은 필수입니다. 모집단 표본에 해당하는 첫 번째 숫자 인수입니다.
– number2,… 선택적 요소. 2에서 255까지의 모집단 표본에 해당하는 숫자 인수입니다.
– Number1, Number 또는 “Number”가 인수로 입력됩니다. 일반적으로 숫자를 포함 셀 참조 주소를 지정하여 사용하다.
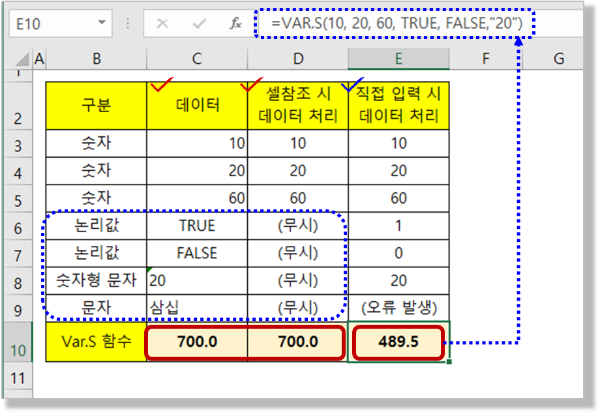
– “숫자”에 특별한주의를 기울여야합니다. 비숫자에는 문자, 논리값(참과 거짓), 숫자처럼 보이는 문자가 포함됩니다.
– 엑셀에서 분산, 표준편차 등의 함수를 사용할 때 숫자인지 아닌지 등 다음 부분에 주의하세요.그리고 당신은 그것을 사용할 수 있습니다.
– 물론 내가 사용하는 통계 함수의 통계적 의미를 알아야 결과 데이터를 효율적으로 사용할 수 있다. ^^
– ① 모집단 또는 표본집단의 어떤 기능을 사용하는가? – 거의 모두 샘플 그룹임(Var.S 함수 또는 Var 함수 사용)
– ② 논리값이나 텍스트 형태의 데이터가 있는 경우 계산을 수행하기 전에 반드시 숫자로 변환하십시오. – 모두 무시했습니다.
– 문자인 경우 논리값 “직접 인수 값으로 입력”의 경우는 “셀 참조 형식”의 입력과 다릅니다.
– 실제로 인수로 데이터를 개별적으로 직접 입력하는 경우는 없으므로 공정하다. 결과적으로 당신은 그것들을 모두 무시한다는 것을 이해할 수 있습니다.
4. Var 함수를 사용해보십시오 – 분산 찾기
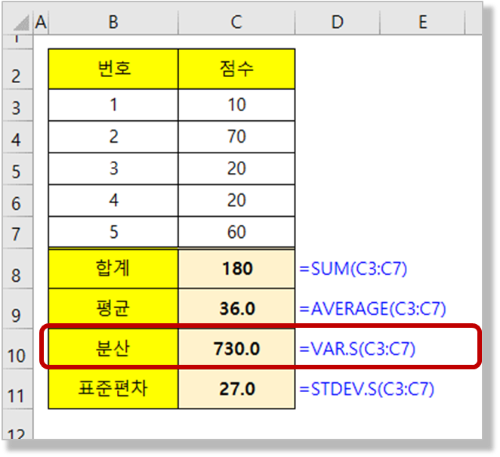
– 다음 반 성적에 대한 분산을 찾아보자.
– Var 함수는 Var.S 함수와 동일한 함수로 표본군( = 표본, 표본군)에 대한 분산을 계산합니다.보지마.
– 가능하면 Var함수 대신 Var.S함수를 사용한다.
– 사용방법은 합계, 평균 등의 기능과 동일합니다. 함수를 입력하고 마우스로 셀 참조 주소를 지정하여 등록할 수 있어요.
– 데이터 분석 시 공통 통계 함수 사용 합계, 평균, 표준 편차, 최대, 최소 정확도.
– 더 다양한 통계 분석이 있지만 가장 기본적인 기능입니다.
– 그리고 평균에 관해서는 약간 다른 평균이 있습니다. 산술 평균(average function), 중앙값(median function) 및 최빈값(mode function)있다
– 대부분 산술평균(average function)을 사용하지만 상황에 따라 조금씩 다르게 사용되오니 참고하시기 바랍니다.
– 그리고 이 모든 통계 분석은 “숫자”에 관한 것입니다.데이터 관리를 잘하는 것이 중요하다고 생각합니다.
– 오늘도 수고하셨습니다.
** 핵심 요약: Var 함수 사용법 – 분산을 찾아보자(Varp, Var.p, Var.s 함수)
1. 기능 설명
– Var 함수는 분산을 계산하는 통계 함수입니다.
분산은 데이터 세트가 평균이라고 하는 중심 값에서 얼마나 떨어져 있는지를 나타내는 통계 수치입니다.
– 실무에서는 표준편차(Stdev 함수)나 변동계수 CV를 많이 사용한다.
2. 분산 – 통계에 대한 기본적인 이해
– 1) 분산: 평균에서 벗어난 정도
– 합계가 0이 되지 않도록 “(데이터 – 평균)^2″로 차이를 제곱합니다.
– 모집단의 경우 데이터의 개수 n으로 나누고 표본집단의 경우 (n-1)로 나눕니다.
– 2) 분산: 모집단의 분산, 표본집단의 분산
– 거의 모든 표본 집단에 대해 전체 값이 측정 가능하거나 알려진 경우 공식을 사용하여 모집단 분산을 계산합니다.
– Population Variance: VAR.P 함수 (VARP 함수 – Excel 2007 이전 버전 함수)
– 표본군 분산: VAR.S 함수(VAR 함수 – Excel 2007 이전 버전 함수)
3. Var 함수 구문/사용법
– VAR(숫자1, (숫자2),…)
– 1번은 필수입니다. 모집단 표본에 해당하는 첫 번째 숫자 인수입니다.
– number2,… 선택적 요소. 2에서 255까지의 모집단 표본에 해당하는 숫자 인수입니다.
– number1, number, 즉 “number”가 인수로 입력됩니다. 일반적으로 숫자가 포함된 셀 참조 주소는 마우스로 지정하여 사용합니다.
– ① 모집단 또는 표본집단의 어떤 기능을 사용하는가? – 거의 모두 샘플 그룹임(Var.S 함수 또는 Var 함수 사용)
– ② 논리값이나 텍스트 형태의 데이터가 있는 경우 계산을 수행하기 전에 반드시 숫자로 변환하십시오. – 모두 무시했습니다.
4. Var 함수를 사용해보십시오 – 분산 찾기
– Var함수는 Var.S함수와 동일한 함수로 표본집단(=표본, 표본집단)에 대한 분산을 계산하는 함수이다.
– 사용방법은 sum, average 함수와 동일하게 함수를 입력하고 셀 참조 주소를 마우스로 지정하여 등록합니다.
– 공식: =VAR.S(C3:C7)
(엑셀함수 코스-플러스) – 999. 엑셀함수 플러스 목차
999. 엑셀 기능 플러스 목차 (Excel Function Course-Plus) – 001. (Excel Function Plus) 문자함수 사용법 – 원하는 형식(형식, 날짜/시간, 소수점, 퍼센트, 시간, 요일)을 문자(Excel 기능 코스- 플러스) – 002 .(엑셀 기능 플러스) Tr nextmeok.tistory.com
* 엑셀 관련 문의사항이나 어려움이 있으시면 연락주세요.
* 가능한 한 최선을 다해 도와드리겠습니다.
*저도 잘 모르지만 다른 사람들처럼 시작이 있고 경험이 다릅니다.
* 저희에게 연락 주시기 바랍니다. 나도 모를 수도 있다. 이것을 고려하십시오.
-ILU, SH-