LFU 캐시 제거 체계를 구현하는 O(1) 알고리즘
Ketan Shah 교수, Anirban Mitra, Dhruv Matani
2010년 8월 16일
추상적인
캐시 제거 알고리즘은 애플리케이션에서 사용하는 데이터를 캐싱하여 실행 속도를 높이기 위해 캐시를 사용하는 운영 체제, 데이터베이스 및 기타 시스템에서 일반적으로 사용됩니다. 다음과 같은 많은 지침이 있습니다.
MRU(가장 최근에 사용됨), MFU(가장 많이 사용됨), LRU(가장 최근에 사용됨), LFU(가장 적게 사용됨) 등과 같은 다양한 정책이 있습니다. 각각 장단점이 있으므로 구체적인 시나리오에 따라 사용됩니다. 지금까지 가장 널리 사용되는 알고리즘은 O(1) 작업 속도와 대부분의 응용 프로그램에서 예상되는 동작 유형에 매우 가깝기 때문에 LRU입니다. LFU 알고리즘은 많은 실제 워크로드에서도 잘 수행됩니다. 그러나 많은 경우에 LRU 알고리즘은 LFU 알고리즘보다 선호되는데 그 이유는 런타임 복잡도가 O(log n)에 비해 O(1)에 불과하기 때문입니다. 여기에서는 모든 작업에 대해 런타임 복잡성 O(1)을 갖는 LFU 캐시 제거 알고리즘을 소개합니다. 런타임 복잡성은 삽입, 액세스 및 삭제(제거)를 포함한 모든 작업에 대해 O(1)입니다.
1. 소개
이 문서는 다음과 같이 구성되어 있습니다.
- 다른 캐시 제거 알고리즘보다 우수함을 입증할 수 있는 LFU의 사용 사례를 설명하십시오. 다른 캐시 제거 알고리즘보다 우수함을 입증할 수 있는 LFU의 사용 사례 설명
- LFU 캐시 구현에서 지원해야 하는 사전 작업입니다. 전략의 런타임 복잡성을 결정하는 작업은 다음과 같습니다. 런타임 복잡성
- 현재 가장 잘 알려진 LFU 알고리즘에 대한 설명이 포함된 런타임 복잡성
- 제안된 LFU 알고리즘에 대한 설명으로 모든 연산의 런타임 복잡도는 O(1)
2. LFU 사용
HTTP 프로토콜을 위한 캐싱 네트워크 프록시 애플리케이션을 고려해 봅시다. 이 프록시는 일반적으로 인터넷과 사용자 또는 사용자 그룹 사이에 위치합니다. 모든 사용자가 인터넷에 액세스하고 공유 가능한 모든 리소스를 공유하도록 하여 네트워크 활용을 최적화하고 응답성을 개선합니다. 이러한 캐싱 프록시는 제한된 메모리 또는 메모리((4, 8, 7))에서 캐싱할 수 있는 데이터의 양을 최대화해야 합니다. 일반적으로 이미지, CSS 스타일시트 및 JavaScript 코드와 같은 많은 정적 리소스는 최신 버전으로 대체되기 전에 꽤 오랜 시간 동안 캐시될 수 있습니다. 이러한 정적 리소스 또는 프로그래머가 “자산”이라고 부르는 것은 거의 모든 페이지에 포함되어 있으므로 거의 모든 요청에 이러한 리소스가 필요하므로 캐시하는 것이 가장 좋습니다. 또한 네트워크 프록시는 초당 수천 건의 요청을 처리해야 하므로 이를 수행하는 데 필요한 오버헤드를 최소한으로 유지해야 합니다.
이를 달성하려면 거의 사용되지 않는 리소스를 폐기해야 합니다. 따라서 자주 사용하는 자원은 오랜 기간에 걸쳐 스스로 증명해왔으며 거의 사용하지 않는 자원을 희생하여 유지해야 합니다. 물론 과거에 많이 사용된 자원이 미래에는 필요하지 않을 수 있다고 주장할 수도 있지만 대부분의 상황에서 그렇지 않은 것으로 밝혀졌습니다. 예를 들어 사용량이 많은 페이지의 정적 리소스는 해당 페이지의 모든 사용자가 항상 요청합니다. 따라서 이러한 캐싱 프록시의 디스크 공간이 부족할 때 LFU 캐시 회전 전략을 사용하여 캐시에서 가장 적게 사용된 항목을 제거할 수 있습니다. LRU도 여기서 적용 가능한 전략일 수 있지만 요청 패턴이 캐시에서 요청된 모든 항목과 일치하지 않고 항목이 라운드 로빈 방식으로 요청되는 경우 실패할 수 있습니다. LRU를 사용하면 사용자 요청이 캐시에 도달하지 않고 항목이 캐시 안팎으로 계속 흐릅니다. 그러나 동일한 조건에서 LFU 알고리즘은 캐시된 항목의 대부분이 캐시 적중으로 이어지기 때문에 훨씬 더 잘 수행됩니다. 그러나 LFU 알고리즘의 병리학적 거동을 배제할 수 없습니다. 이 기사에서는 LFU의 예를 제시하려는 것이 아니라 LFU가 적용 가능한 전략이라면 지금까지 발표된 것보다 더 나은 구현 방법이 있음을 보여주고자 합니다.
3. LFU 캐시가 지원하는 사전 연산
캐시 배출 알고리즘과 관련하여 기억해야 할 캐시된 데이터에 대한 작업은 주로 세 가지입니다.
- 항목을 캐시에 넣기(또는 삽입하기)
- 캐시에서 항목 검색(또는 조회), 동시 사용 수 증가(LFU의 경우)
- 가장 적게 사용된 항목을 제거(또는 삭제)합니다(또는 제거 알고리즘의 전략에 따라) 캐시에서 항목을 제거(또는 삭제)합니다.
4. 현재 가장 잘 알려진 LFU 알고리즘의 복잡도
이 글을 쓰는 시점에서 위의 각 작업에 대해 가장 잘 알려진 런타임은 다음과 같습니다.
- 삽입: O(log n)
- 검색: O(log n)
- 소거: O(log n)
이러한 복잡성 값은 이진 힙 구현의 복잡성과 충돌 없는 표준 해시 테이블의 복잡성에서 직접 따릅니다. LFU 캐싱 전략은 최소 힙 데이터 구조와 해시 맵을 사용하여 쉽고 효율적으로 구현할 수 있습니다. 최소 힙은 (요소의) 사용 횟수를 기반으로 구축되고, 해시 테이블은 요소를 기반으로 구축되며, 해시 테이블은 요소의 키로 인덱싱됩니다. 충돌 없는 해시 테이블의 모든 작업은 O(1) 차수이므로 LFU 캐시의 실행 시간은 최소 힙((5, 6, 9, 1, 2 )). . 요소가 캐시에 삽입되면 사용 횟수는 1이 되고 최소 힙에 삽입하는 데 O(log n)의 비용이 들므로 LFU 캐시에 삽입하는 데 O(log n)이 걸립니다((3)). . 항목을 조회할 때 실제 항목의 키를 해시하는 해시 함수를 사용하여 찾습니다. 동시에 사용 횟수(최대 힙 수)가 1씩 증가하여 최소 힙이 재구성되고 요소가 루트에서 제거됩니다. 요소가 각 단계에서 log n 레벨 아래로 이동할 수 있기 때문에 이 작업도 O(log n) 시간이 걸립니다. 제거를 위해 요소가 선택되고 결국 힙에서 제거되면 힙 데이터 구조가 크게 재구성될 수 있습니다. 가장 적게 사용되는 요소는 최소 힙의 루트에 있습니다. 최소 힙의 루트를 삭제하려면 루트 노드를 힙의 마지막 리프 노드로 교체하고 해당 노드를 제자리로 버블링해야 합니다. 이 작업은 또한 O(log n)의 런타임 복잡도를 가집니다.
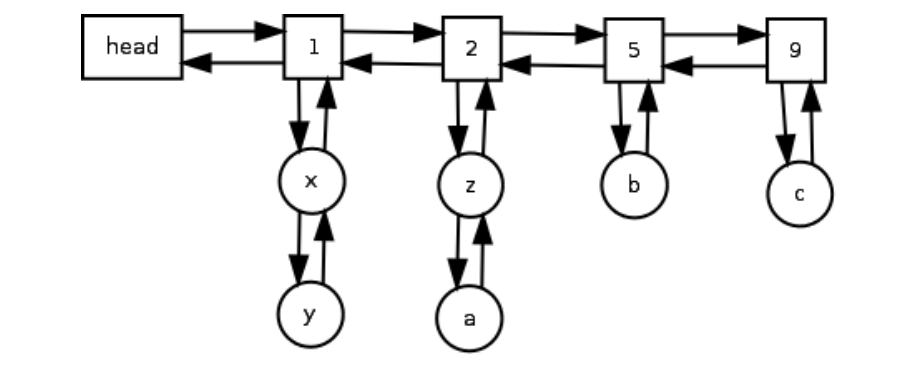
5. 제안하는 LFU 알고리즘
제안하는 LFU 알고리즘은 LFU 캐시에서 수행할 수 있는 각 사전 연산(삽입, 검색, 삭제)에 대해 O(1)의 런타임 복잡도를 갖는다. 이는 두 개의 연결 목록을 유지함으로써 달성됩니다. 하나는 액세스 빈도에 대한 것이고 다른 하나는 동일한 액세스 빈도를 가진 모든 항목에 대한 것입니다. 해시 테이블은 키로 항목에 액세스하는 데 사용됩니다(명확성을 위해 아래 다이어그램에는 표시되지 않음). 이중 연결 목록은 액세스 빈도가 동일한 노드 집합을 나타내는 노드를 함께 연결하는 데 사용됩니다(아래 그림에서 직사각형 블록으로 표시됨). 블록으로 표시). 이 이중 연결 목록을 주파수 목록이라고 합니다. 동일한 액세스 노드 집합은 실제로 해당 노드의 이중 이중 연결 목록입니다(아래 다이어그램에서 원형 노드로 표시됨). 우리는 이 이중 연결 목록(특정 빈도로 제한됨)을 노드 목록이라고 합니다. 노드 목록의 각 노드에는 상위 노드에 대한 포인터가 있습니다. 주파수 목록에 대한 포인터가 있습니다(명확성을 위해 다이어그램에는 표시되지 않음). 따라서 노드 x와 y에는 노드 1에 대한 포인터가 있고 노드 z와 a에는 노드 2에 대한 포인터가 있습니다. 2 등등…
아래 의사 코드는 LFU 캐시가 초기화되는 방법을 보여줍니다. 키로 항목을 찾기 위한 해시 키로 항목을 조회하는 데 사용되는 테이블은 변수 bykey로 표시됩니다. 동일한 액세스 빈도로 항목을 저장하기 위해 연결된 목록 대신 집합을 사용합니다. 구현을 단순화하기 위해 Linked List 대신 SET를 사용합니다. 변수 요소는 표준 SET 데이터입니다.
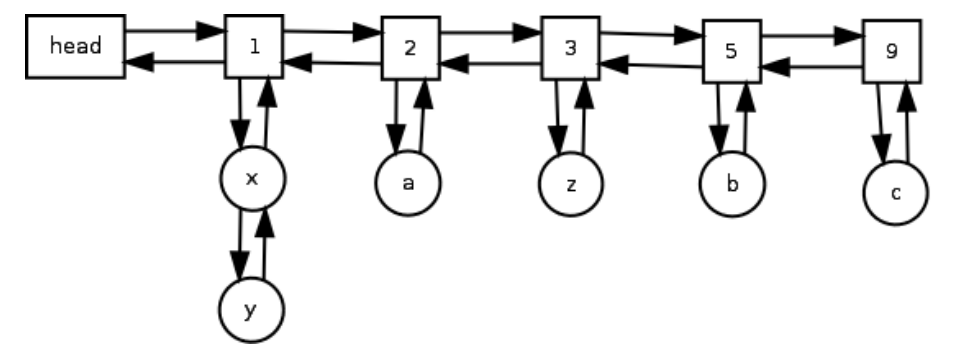
구조체에는 액세스 빈도가 동일한 요소의 키가 포함됩니다. 런타임 복잡성 삽입, 검색, 삭제는 O(1)입니다.
액세스 빈도 값이 0인 새 “주파수 노드”를 만듭니다.
NEW-FREQ-NODE()
01 개체 또는
02 o.값 ← 0
03 또는 요소 ← SET()
04 o.뒤로 ← o
05 이상 ← 또는
06 리턴 오
조회 테이블에 bykey로 저장된 새 LFU 항목을 만듭니다.
NEW-LFU-ITEM(데이터, 부모)
01 개체 또는
02 오.데이터 ← 데이터
03 o.부모 ← 부모
04 리턴 오
새 LFU 캐시 생성
NEW-LFU-CACHE()
01 개체 또는
02 o.bykey ← HASH-MAP()
03 주파수 헤드 ← NEW-FREQ-NODE
04 리턴 오
LFU 캐시 개체는 lfu 캐시 변수를 통해 액세스할 수 있습니다.
LFU 캐시 ← NEW-LFU-CACHE()
또한 연결된 목록의 조작을 지원하는 일부 도우미 함수를 정의합니다.
새 항목을 만들고 이전 및 다음 항목 포인터를 이전 및 다음 항목으로 설정합니다.
새 노드 가져오기(가치, 이전, 다음)
01nn ← NEW-FREQ-NODE()
02 nn.값 ← 값
03 nn.prev. ← 이전
04 nn.계속 ← 계속
05 이전.다음 ← nn
06 next.이전 ← nn
07 반환 nn
연결된 목록에서 노드를 제거합니다(연결 해제).
노드 삭제(노드)
01 노드.이전.다음 ← 노드.다음
02 노드.다음.이전 ← 이전
처음에 LFU 캐시는 빈 해시 맵과 빈 주파수 목록으로 시작합니다. 첫 번째 요소가 추가되면 해시 맵에서 이 새 요소를 가리키는 단일 요소(bykey)가 생성되고 값이 1인 새 빈도 노드가 생성되며 값이 1인 노드가 빈도 목록에 추가됩니다. 해시 맵의 요소 수 해시 맵의 요소 수는 LFU 캐시의 항목 수와 같아야 합니다. 주파수 1 목록에 새 노드가 추가됩니다. 이 노드는 실제로 자신이 속한 주파수 노드를 다시 가리킵니다. 예를 들어 x가 추가된 노드인 경우 노드 x는 다시 주파수 노드 1을 가리킵니다. 따라서 요소 삽입의 런타임 복잡도는 O(1)입니다.
LFU 캐시에서 액세스(가져오기)되는 동안 항목이 사용된 횟수입니다.
액세스 키)
01 tmp ← lfu 캐시.bykey(키)
02 tmp가 0이면
03 예외 발생(“해당 키 없음”)
04 주파수 ← tmp.Parent
05 다음 주파수 ← 주파수.다음
06
07 다음 주파수가 lfu cache.freq 헤드와 같거나
08 다음 Freq.Value는 Freq.Value + 1과 같지 않습니다.
08 다음 주파수 ← GET-NEW-NODE(주파수.값 + 1, 주파수, 다음 주파수)
09 다음 freq.items.add(key)
10 tmp.parent ← 다음 주파수
11
12개의 공통 항목(키) 제거
13 freq.items.length가 0이면
14 노드 삭제(주파수)
15 임시 데이터 백
이 요소에 다시 액세스하면 요소의 빈도 노드가 조회되고 가장 가까운 형제의 값이 쿼리됩니다. 형제 노드가 존재하지 않거나 다음 형제 노드의 값이 이 요소의 값보다 1이 크지 않으면 해당 빈도 노드의 값보다 1 큰 값을 가진 새 빈도 노드가 1보다 큰 값으로 설정됩니다. 이 주파수 노드의 값으로 재생성되어 올바른 위치에 붙여넣어집니다. 현재 세트에서 노드가 제거되고 새 빈도 목록 세트에 삽입됩니다. 노드의 주파수 포인터는 새 주파수 노드를 가리키도록 업데이트됩니다. 예를 들어 노드 z가 다시 접근되면(1) 빈도 목록에서 제거되고, 빈도 목록의 값으로 빈도 목록에서 제거되고, 값 3으로 빈도 목록에 추가됩니다(2). 따라서 요소 액세스의 런타임 복잡성은 O(1)입니다.
LFU 캐시에 새 항목을 삽입합니다.
INSERT(키, 값)
01 if key in lfu cache.bykey 다음
02 throw 예외(“키가 이미 존재함”)
03
04 주파수 ← lfu 캐시.주파수 헤드.다음
05 주파수 값이 1이 아닌 경우
06 freq ← GET-NEW-NODE(1, lfu 캐시. freq 헤드, freq)
07
08 freq.items.add(키)
09 lfu 캐시.bykey(키) ← NEW-LFU-ITEM(값, 빈도)
가장 적게 본 항목을 삭제해야 하는 경우 가장 많이 사용한 첫 번째(가장 왼쪽) 목록에서 항목을 선택하고 제거합니다. 이 삭제로 인해 해당 주파수 목록의 노드 목록이 비어 있는 경우 주파수 노드도 삭제됩니다. 해시맵의 요소에 대한 참조도 삭제됩니다. 따라서 가장 적게 사용된 요소를 삭제하는 런타임 복잡도는 O(1)입니다.
캐시에서 가장 적게 사용된 항목(가장 적게 사용된 항목)을 가져옵니다.
LFU 항목 가져오기()
lfu cache.bykey.length가 0이면 01
02 throw Exception(“세트가 비어 있습니다.”)
03 return lfu cache.bykey( lfu cache.freq head.next.items(0) )
따라서 LFU 캐시에 있는 각 사전 작업의 런타임 복잡도는 O(1)입니다.
참조
(1) 반효경, 민상렬 노삼현, 고건, 웹캐시에서 효율적인 문서 교체를 위한 전체 참조 이력 사용, usenix(1999).
(2) Sorav Bansal 및 Dharmendra S. Modha, 자동: 적응형 교체가 있는 시계, usenix(2004).
(3) Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, Clifford Stein, Introduction to algorithms, 2판, (2002), 130–132.
(4) G. Karakostas 및 DN Serpanos, 웹 캐싱을 위한 실용적인 IFU 구현(2000년 6월 19일).
(5) 이동희, 최종무, 김종훈, 노삼현, 민상률, 조요근, 김종상, Lrfu: A Spectrum of Policies, In including the Least Recent Used and the Least Commonly Used Policies, (3월 10, 2000).
(6) Elizabeth J O’Neil, Patrick E O’Neil 및 Gerhard Weikum, lru-k 페이지 대체 알고리즘의 최적성 증명, (1996).
(7) 심준호, Peter Scheuermann 및 Radek Vingralek, 프록시 캐시 설계: 알고리즘, 구현 및 성능, 지식 및 데이터 엔지니어링에 관한 IEEE 트랜잭션(1999).
(8) Dong Zheng, 세분화된 웹 캐싱 – 프록시에 대한 세분화된 메모리 할당 모델, (2004).
(9) Yuanyuan Zhou 및 James F. Philbin, 2단계 버퍼 캐시를 위한 다중 대기열 교체 알고리즘, usenix(2001).